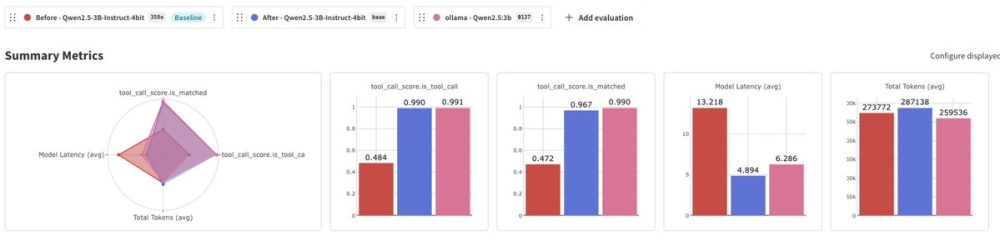
MLX Omni Server v0.2.0: A Leap in Function Calling Accuracy
The latest release of MLX Omni Server v0.2.0 has brought significant advancements in function calling accuracy. The improvements are particularly notable in the Llama3.2 3B (4bit) and Qwen2.5 3B (4bit) models. The Llama3.2 3B model has seen an impressive increase in accuracy from 2.9% to 99.6%, while the Qwen2.5 3B model has improved from 48.4% to 99.0%. These enhancements mean that users can now run powerful AI tools locally on their Mac with minimal latency.
Meta’s Llama 3 Models: Boosting Open Source AI
Meta Platforms, Inc. has been making waves in the AI community with its Llama 3 models. The open-source nature of these models allows for greater transparency and community-driven development, setting them apart from closed-source models from competitors like OpenAI. The Llama 3 models are designed to cater to AI researchers, developers, and companies seeking to leverage large language models (LLMs) for various applications, including natural language processing, text generation, translation, summarization, and code generation. For more details, visit Meta’s new Llama 3 models give open source AI a boost.
Ai2’s OLMo 2: Advancing Open Source AI
The Allen Institute for AI (Ai2) has unveiled its second open language model, OLMo 2. This model is open source according to the Open Source Initiative’s definition, meaning that the tools and data used to develop it are available to the public. Ai2 has reported a considerable improvement in performance compared to their previous OLMo 0424 model, with the OLMo 2 7B outperforming Meta’s Llama-3. For more information, visit Ai2 unveils second open language model OLMo 2.
Mistral’s Large 2: Competing with Meta and OpenAI
Mistral has released its Large 2 AI model, which outpaces competitive models on code generation and math performance with a third of the parameters. The model features a 128,000 token window, making it a formidable competitor in the AI landscape. For more details, visit Mistral’s Large 2 is its answer to Meta and OpenAI’s latest models.
Alibaba’s Qwen Team: Building LLMs in China
Alibaba’s Qwen team has been working on large language models (LLMs) with a focus on multilingual capabilities, including Southeast Asian languages. These models are integrated with existing Alibaba services like DingTalk and Tmall, making them highly versatile for enterprise communication and online retail. For more information, visit Alibaba staffer offers a glimpse into building LLMs in China.
Microsoft’s Inference Framework for 1-bit LLMs
Microsoft has launched an inference framework to run 100B 1-bit large language models on local devices. The BitNet.cpp framework can run a 100B BitNet b1.58 model on a single CPU, achieving processing speeds comparable to human reading, at 5-7 tokens per second. For more details, visit Microsoft Launches Inference Framework to Run 100B 1-Bit LLMs on Local Devices.
Related Articles
- Alibaba’s Qwen: A New Contender in the AI Landscape
- Pushing the Boundaries of LLM Optimizations with Pruning and Quantization
- The Impact of LLMs and Quantum Computing on Fundamental Science
- LangWatch: A Smooth Experience in LLM Program Optimization
- Peng v0.5.3: Enhancing Quadrotor Autonomy with Rust
Looking for Travel Inspiration?
Explore Textify’s AI membership
Need a Chart? Explore the world’s largest Charts database