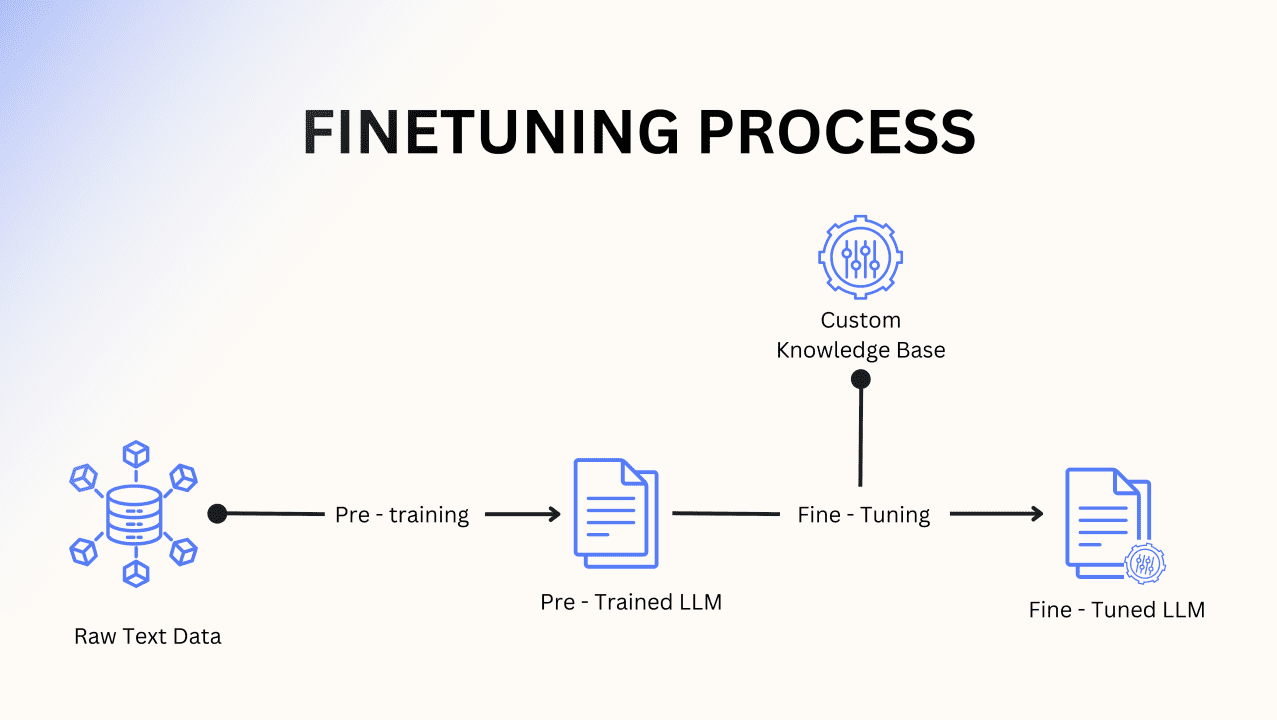
The Adaptation Odyssey: Understanding the Challenge
Fine-tuning large language models (LLMs) on domain-specific data doesn’t always lead to improved performance. This phenomenon, termed the ‘Adaptation Odyssey,’ is a significant challenge in the field of artificial intelligence (AI) and natural language processing (NLP). A recent paper presented at EMNLP 2024 by Firat Oncell and his team delves into the reasons behind this issue.
Why Fine-Tuning Doesn’t Always Work
Fine-tuning LLMs involves adapting a pre-trained model to a specific domain by training it further on domain-specific data. While this approach aims to enhance the model’s performance in that particular domain, it often leads to mixed results. The primary reasons for this include:
- Overfitting: The model may become too specialized, losing its generalization ability and performing poorly on broader tasks.
- Data Quality: Domain-specific data may not always be of high quality or sufficient quantity, leading to suboptimal fine-tuning.
- Catastrophic Forgetting: The model may forget previously learned information, impacting its overall performance.
The Impact of Model Collapse
The concept of ‘model collapse’ is closely related to the Adaptation Odyssey. As highlighted in a TechCrunch article, model collapse occurs when AI systems are trained on data generated by other AI systems, leading to a degradation in performance over time. This issue is exacerbated by the increasing prevalence of AI-generated content on the web, which can contaminate training datasets.
For more insights on model collapse, refer to the article: Model Collapse: Scientists Warn Against Letting AI Eat Its Own Tail.
Addressing the Adaptation Odyssey
Researchers are exploring various strategies to mitigate the challenges of fine-tuning LLMs. Some of these approaches include:
- Regularization Techniques: Implementing techniques to prevent overfitting and maintain the model’s generalization capabilities.
- Data Augmentation: Enhancing the quality and diversity of domain-specific data to improve fine-tuning outcomes.
- Continual Learning: Developing methods to enable models to retain previously learned information while adapting to new data.
The Role of Energy Efficiency
Another critical aspect of fine-tuning Large Language Models is energy efficiency. Researchers have proposed techniques like L-Mul to address the energy-intensive nature of floating point multiplications in LLMs. This method can significantly reduce energy consumption, making the fine-tuning process more sustainable.
For more details on energy-efficient computation in neural networks, refer to the article: 95% Less Energy Consumption in Neural Networks Can be Achieved. Here’s How.
Future Directions and Ethical Considerations
As the field of AI continues to evolve, addressing the Adaptation Odyssey will be crucial for the development of robust and reliable LLMs. Researchers must also consider the ethical implications of fine-tuning, such as the potential for generating biased or harmful content. Transparency and accountability in the use of LLMs are essential to ensure their safe and ethical deployment.
For more information on the ethical considerations of LLMs, refer to the article: Anthropic Researchers Wear Down AI Ethics with Repeated Questions.
Ready to Transform Your Hotel Experience? Schedule a free demo today
Explore Textify’s AI membership
Explore latest trends with NewsGenie