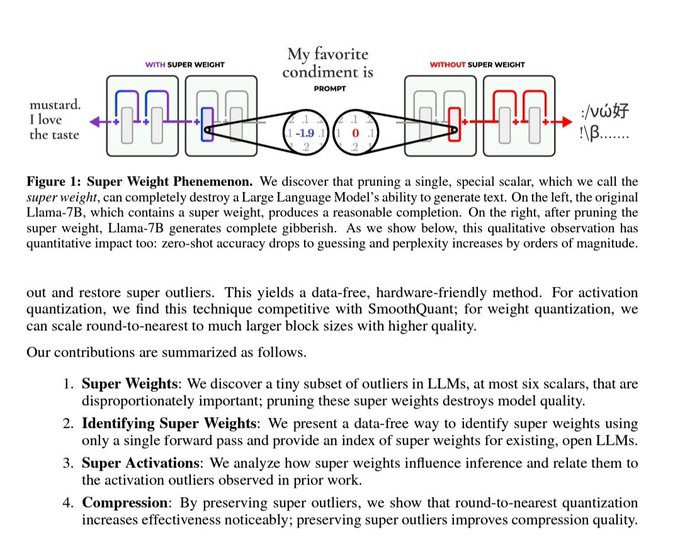
The Impact of Super Weight on LLMs
The recent study highlighted in a tweet by a prominent AI researcher has brought to light a fascinating phenomenon in the realm of Large Language Models (LLMs). The study reveals that altering a single ‘super weight’ can drastically impair an LLM’s ability to generate coherent text and reduce its zero-shot accuracy for downstream tasks to nearly zero. This finding underscores the delicate balance of parameters within these complex models, where even minor changes can lead to significant performance degradation. For more details, you can refer to the original study.
Understanding Super Weights in LLMs
Super weights in LLMs are critical parameters that have a disproportionately large impact on the model’s output. These weights are integral to the model’s ability to understand and generate text. When a super weight is altered, it can disrupt the intricate network of connections within the model, leading to a collapse in its performance. This phenomenon is akin to removing a crucial component from a complex machine, causing it to malfunction.
The Broader Implications for AI Development
The implications of this discovery are profound for the development and deployment of AI models. It highlights the need for robust mechanisms to safeguard the integrity of these weights during training and inference. This is particularly relevant in the context of deploying LLMs in real-world applications, where stability and reliability are paramount.
Microsoft’s Breakthrough in Efficient Inference
In related news, Microsoft has launched an inference framework capable of running 100 billion 1-bit LLMs on local devices. This framework, known as BitNet.cpp, can run a 100B BitNet b1.58 model on a single CPU, achieving processing speeds comparable to human reading, at 5-7 tokens per second. This development represents a significant step forward in making powerful AI models more accessible and energy-efficient. For more information, visit Microsoft Launches Inference Framework.
The Challenge of Model Collapse
The phenomenon of model collapse, where an AI model’s performance deteriorates due to internal feedback loops, is another critical area of concern. Scientists have warned against letting AI models ‘eat their own tail,’ as this can lead to a significant decline in their ability to generate accurate and reliable outputs. This issue is particularly relevant in the context of LLMs, where the integrity of super weights is crucial. For a detailed discussion on this topic, refer to the article on Model Collapse.
Meta’s Open AI Model and Computational Demands
Meta has recently released its biggest open AI model yet, which underscores the growing computational demands of training advanced LLMs. Mark Zuckerberg has stated that Meta will need ten times more computing power to train Llama 4 than Llama 3, highlighting the escalating resource requirements for developing state-of-the-art AI models. For more insights, read the article on Meta’s Computational Demands.
Energy Efficiency in Neural Networks
Researchers are also exploring ways to reduce the energy consumption of neural networks. A new technique called L-Mul has been proposed, which addresses the problem of energy-intensive floating-point multiplications in LLMs. This method could potentially reduce energy consumption by up to 95%, making AI models more sustainable. For more details, visit Energy Efficiency in Neural Networks.
Related Articles
- The Adaptation Odyssey: Challenges in Fine-Tuning Large Language Models (LLMs)
- 5 Ways to Implement AI into Your Business Now
- Exploring the LLM Engineer’s Handbook: A Comprehensive Guide for AI Researchers
- Exploring the Inner Workings of Large Language Models (LLMs)
- Human Creativity in the Age of LLMs
Looking for Travel Inspiration?
Explore Textify’s AI membership
Need a Chart? Explore the world’s largest Charts database